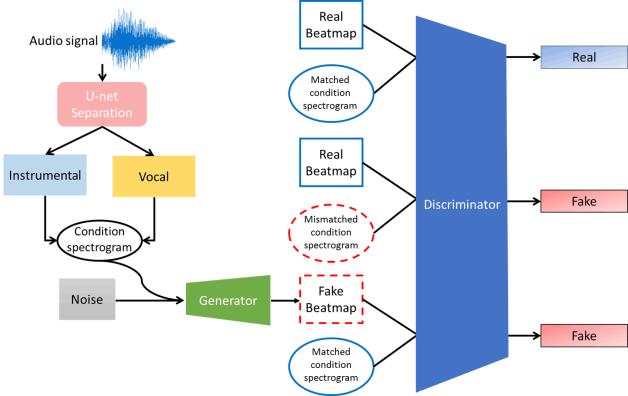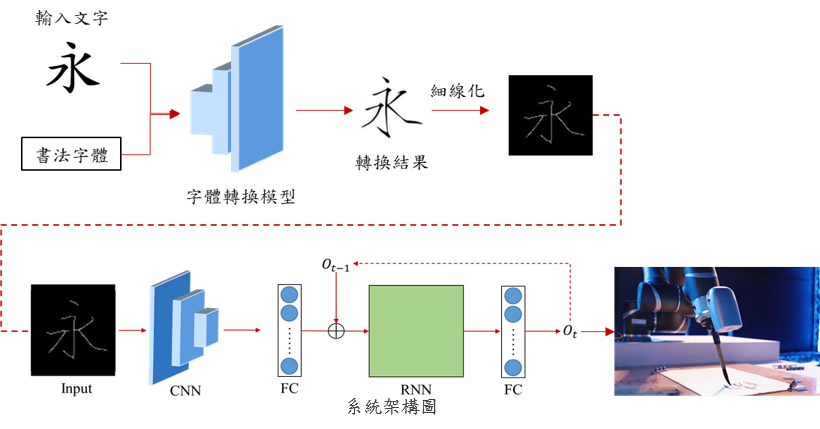
Writing calligraphy on obot
The research includes three areas of artistic creation, robotic automation, and
artificial intelligence(AI). The AI technology is used to construct writing style of
famous calligrapher, and writing with the arm.
Calligraphy style transfer:
In the process of calligraphy style transfer, the method is based on CycleGAN. With a
improvement of adding embedding layers to overcome that a single model can only convert
a different style limit. By collecting the wrist movements during writing, the robot can
simulate the calligrapher's writing. After the calligraphy are written.
Generating stroke orders and robot trajectory:
Thining the transferred calligraphy lets the robotic arm simulate the calligrapher's
writing action to write the calligraphy characters, we need to convert the coordinates
of the thinned images to get the six-axis data. The six-axis sequence data of the
calligraphy is provided to the robot arm for writing the calligraphy characters.
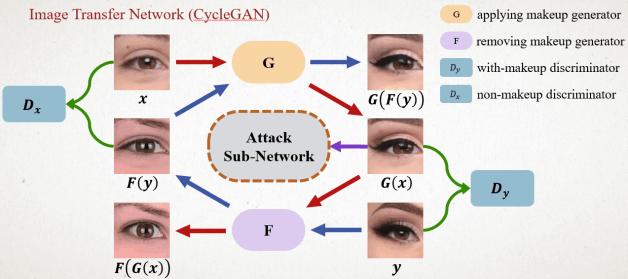
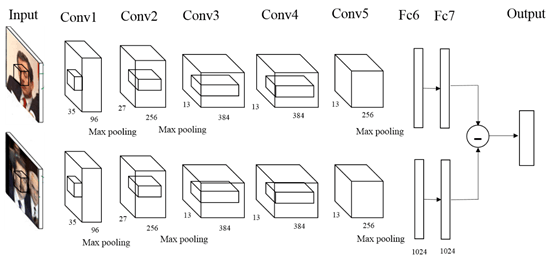
Incorporating attack information into makeup to attack deep learning models
Machine learning has evolved very rapidly, with good results in both computer vision and natural language processing. There are many deep learning techniques that are used in everyday life of humans such as autonomous vehicles and face recognition systems. Nowadays, the gradual dependence of human daily life on deep neural networks can lead to serious consequences, so the security of neural networks becomes very important. Therefore, the deep neural network has obvious weaknesses. We propose a method based on generating a confrontation network to generate a facial makeup picture that can deceive the face recognition system. We hide the perturbation of the attack in the results of the abnormal makeup photos that humans can’t detect. The experimental results show that we can not only generate high-quality facial makeup images, but also our attack results have a high attack success rate in the face recognition system.