Our Researches
實驗室近年研究方向與成果

CCUMVL-Vehicle-ReID DATASET
本資料集是車輛re-id用途的資料集,車輛路線選自 嘉義縣鐵路警察局太保分局 經 高鐵西路延嘉朴公路 至 朴子加油站,沿途共計 8 台攝影機所拍攝。
更多細節詳見 Download page。
請先閱讀授權文件並提出資料及申請。
link:
License Link
Apply From Link
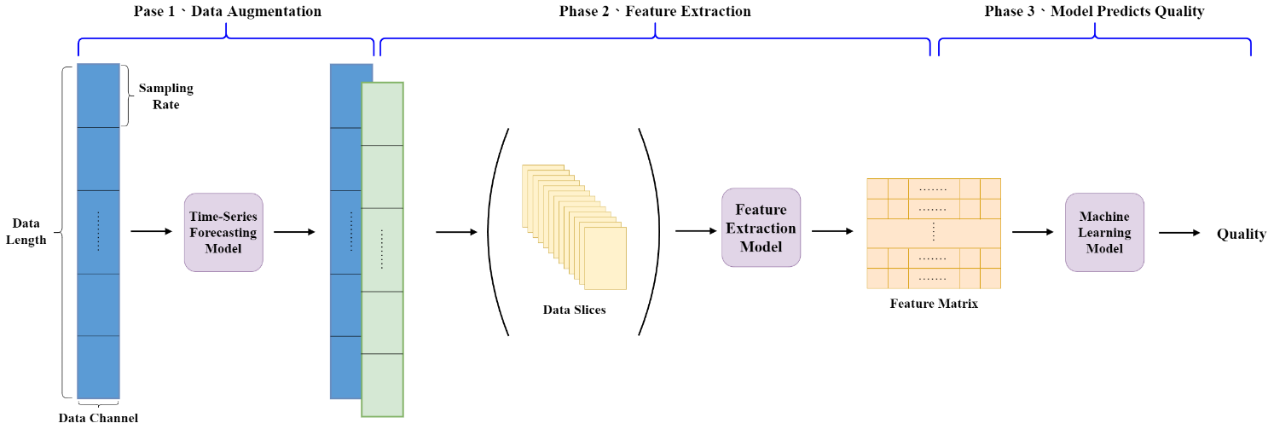
通過深度學習進行超長時間序列資料擴增以進行矽晶圓品質預測
在晶圓研磨過程中,通常會在研磨機中安裝傳感器來監控磨損過程並預測產品品質。但是,標記時間序列資料非常耗時。 因此,本研究旨在基於深度學習模型進行超長時間序列資料擴增。資料擴增通過晶圓品質預測模型進行驗證。在本報告中, 提出的資料擴增深度學習方法分為三個階段:資料擴增生成、特徵表示學習和預測品質模型。 第一階段是資料擴增生成。Temporal Pattern Attention Long short-term memory(TPA-LSTM)模型用於實現資料擴增。 第二階段是特徵提取,將基於Long short-term memory(LSTM)模型或自動編碼器模型擷取資料特徵。期望將原始訊號資料 的高維度空間轉化為低維度的特徵表示,以減輕模型學習的負擔。在模型訓練過程中,考慮使用資料切片方法進一步減小模型 大小和計算複雜度。第三階段是品質預測。這是為了評估不同擴增方法、不同特徵擷取方法和不同模型下的穩定性。 實驗結果表明,當將所擷取的資料擴增方法用於非常長的時間序列資料生成時,性能得到了卓越的提升。在真實世界的晶圓研 磨資料集上,改善率高達 98.42%。
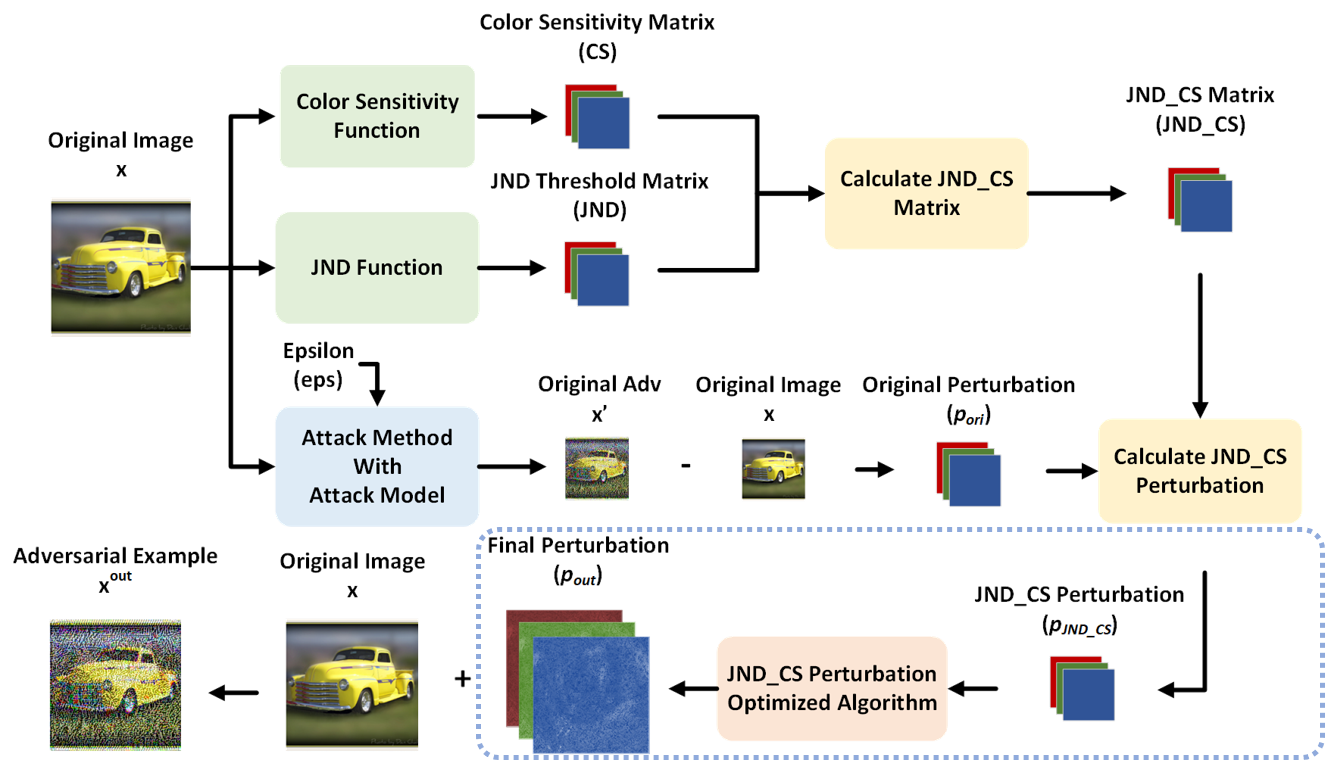
基於視覺知感特性產生攻擊影像
在近期的研究中表明,在影像中加入雜訊可以使深度神經網路(Deep Neural Networks, DNN)受到影響,而加入雜訊後的影像稱為對抗性樣本(Adversarial Example)。其中,加入大量雜訊的對抗性樣本可以使DNN受到較大的影響,但在 視覺感知上也較容易察覺對抗性樣本與原始影像的不同。為了改善對抗性樣本的影 像品質,本文基於感知視覺特性提出了通用增強方法以及對抗性攻擊(Adversarial Attack)方法,其中感知視覺特性包含光譜敏感度(Spectral Sensitivity)以及最小可 覺差(Just Noticeable Difference, JND)。我們所提出的方法將與現有的對抗性攻擊 方法相結合,展現出我們的方法具有通用性。除此之外,也可獨立成為對抗性攻擊 方法。透過實驗表明,我們的方法在某些情況下可以提升現有方法的攻擊成效,並 改善對抗性樣本的影像品質。
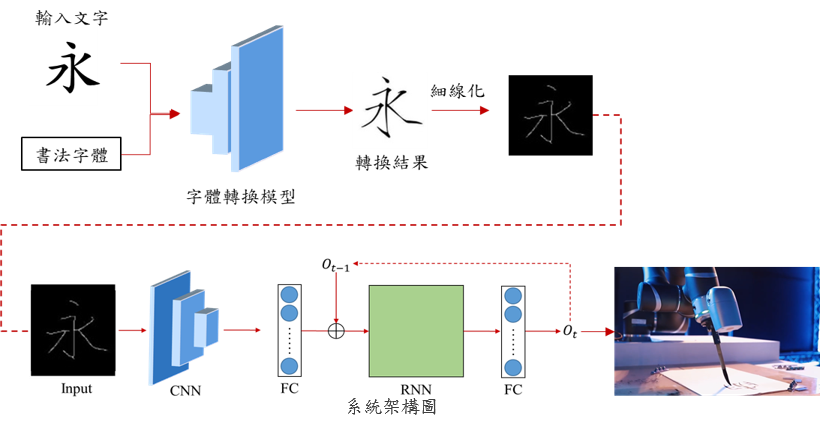
機器人寫書法
此項研究包含藝術創作、機器人自動化、及人工智慧三領域,透過AI技術建構名家書寫風格,以手臂臨摹出人類書寫動作。
字體風格轉換:
在書法字體轉換過程,改進以生成對抗網路為基礎的CycleGAN,突破單一模型只能轉換一種不同字體的限制,
並且透過收集書寫時的手腕動作,讓機器手臂能夠模擬書法家的寫法來將轉換後的書法字寫出。
機械手臂骨架軌跡和筆順生成:
利用風格轉換後的字體進行細線化,讓機器手臂模擬書法家的書寫動作將書法字寫出,我們需要將模型轉換後字體的座標、
寬度…等相關資訊搭配收集的書寫動作的六軸資料,使用筆順學習的方法將書法筆順的六軸序列資料提供給機器手臂。
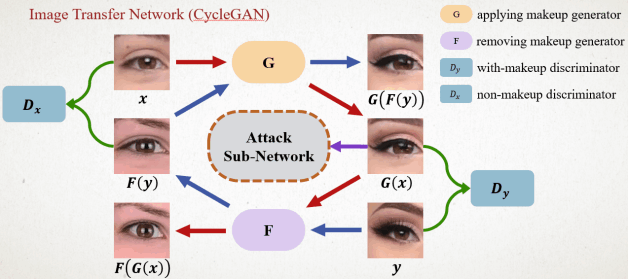
將攻擊資訊包含在化妝中對深度學習模型進行攻擊
機器學習的發展非常迅速,在電腦視覺和自然語言處理方面都有很好的成果。 有許多深度學習技術被運用在人類日常生活當中例如自動駕駛汽車和人臉辨識系統。 如今,人類日常生活漸漸的依賴於深度神經網路可能會導致嚴重的後果,因此神經網路的安全性就變的很重要。 因此展現深度神經網路其實有明顯的弱點,我們提出了一種基於生成對抗網絡的方法來生成可以欺騙人臉識別系統的臉部化妝圖片。 我們在人類無法察覺的異常化妝照片結果中隱藏了攻擊的擾動信息。實驗結果顯示, 我們不但可以生成高畫質的臉部化妝圖像,並且我們的攻擊結果在人臉識別系統中具有很高的攻擊成功率。
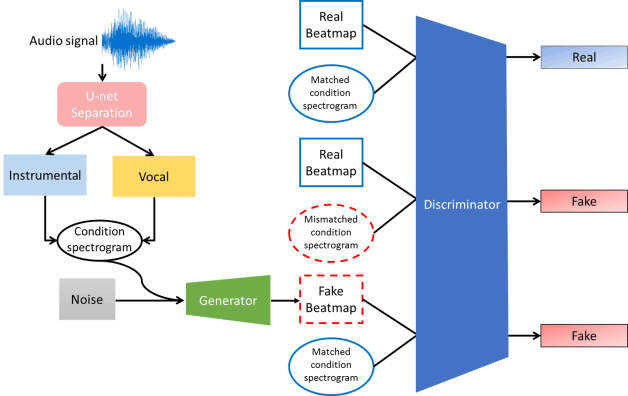
利用生成對抗網路產生音樂節奏遊戲
音樂節奏遊戲是目前非常熱門的遊戲,我們提出了基於生成對抗網路的方法產生音樂節奏遊戲譜面。 音樂被分離為人聲與配樂兩部分,使產生的譜面更貼近真實譜面。 模型包含兩種生成對抗網路的概念:為了加入音樂資訊而採用的Conditional Generative Adversarial Nets (CGANs) 以及使模型更好收斂的Improved Wasserstein GAN (WGAN-GP)。

人人都是藝術家! 塗鴉生成畫作
我們提出一個全自動化的系統,可以將隨意畫的塗鴉轉化成一幅畫作。 然而這是一個嚴峻的挑戰,原因在於輸入的塗鴉可能是非常雜亂並且隱藏著多重物件的, 因此找到這些重複的線條與多重的物件之間的關聯性並不是件簡單的事。在系統當中, 我們結合使用了 selective search、sparse coding 與 Convolutional neural network (CNN), 其中我們運用 selective search 來找尋塗鴉當中可能是物件的部分; 接著利用 sparse coding 來找到相對應的元素;最後藉由 CNN 套上欲轉換的風格。 最終的實驗結果顯示我們所使用的方法有優越的性能並且產生具有藝術性的作品。
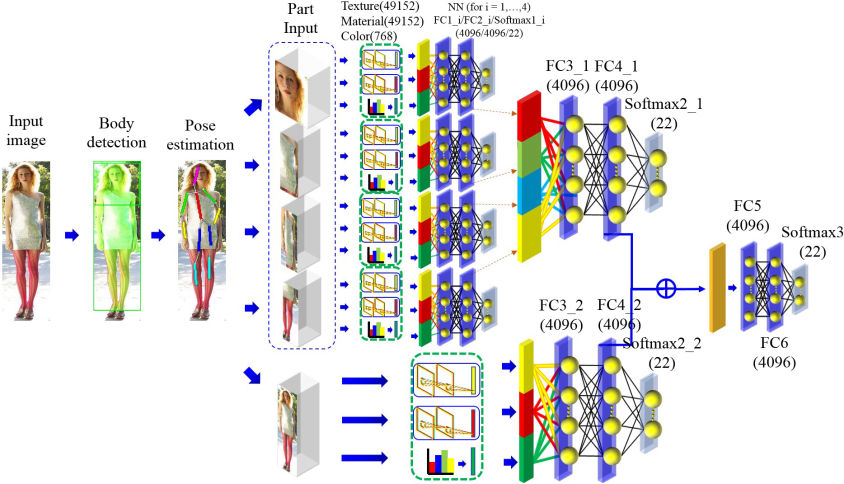
衣著樣式分析與流行元素擷取
隨著衣服和配飾樣式越來越多,無論實體或網路店家,消費者要在眾多樣式中找尋自己喜好的樣式將花費大量的時間, 因此若消費者能給一些喜歡的服飾照片,系統分析照片中服飾找出相關資訊(如店家地址、搭配相關配飾等)。 對店家而言,若能收集到顧客相關服裝風格就可以根據這份資訊調整進貨款式和店裡的擺設, 進一步根據消費者的喜好推薦相關配飾給消費者並節省消費者去尋找能搭配相關配飾時間。 對成衣商而言,能透過各個店家收集的資料加以分析就能知道那些款式受歡迎那些款式不受歡迎,進而成為下一批新款式的設計參考。
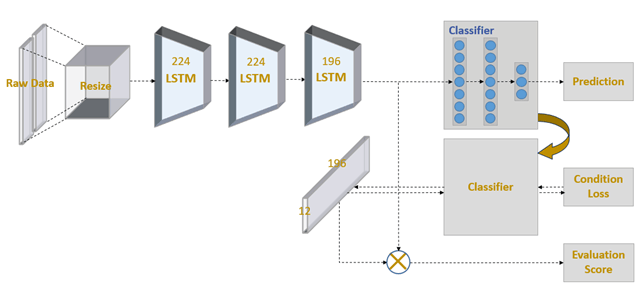
基於感測器的復健動作之深度學習識別與評估
本方法中,我們的目標是在好、中、壞三個評等中,評估四種復健動作,我們提出了一個創新的方法,是藉由學習每個類別的最好特徵表示。 我們的想法是設計一個評估矩陣,而這個矩陣的每個元素對應一個動作的一個評等。 藉由在一個元素中設置最大數字,評估矩陣可以與深度學習模型的輸出層一起使用,以在特定級別推斷該練習的最佳特徵。 評估分數是通過檢查當前特徵的距離度量和該類的最佳特徵來獲得。我們還為復健動作評估收集了一個新的復健動作數據集。 它包含四個不同的復健動作,分別由復健醫師定義。
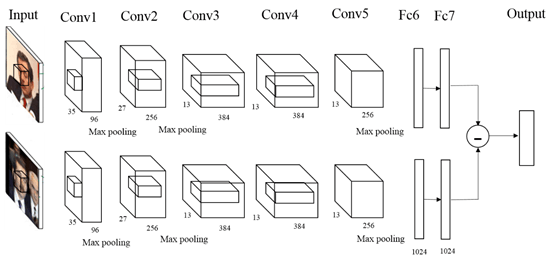
戶外低解析人臉辨識
此計畫目標是對於低解析度的人臉影像進行比對,驗證是否為同一人。 現今在未受限制的環境中,人臉辨識的效能常會因為姿勢的因素而下降,所以我們建立一個姿勢正規化的方法來復原任意的臉部角度, 藉此回復任意狀態的臉部角度以增加人臉辨識的效能。 而此計畫使用了兩種 Caffe 之模型架構: Matching-Convolutional NeuralNetwork (M-CNN)、Siamese Neural Network (SNN)。 最後經實驗結果得到 SNN 模型準確率達 90% 以上,與 M-CNN 相較之下較高。

多重屬性影像分類
進行人臉圖片分類時,欲辨識的圖片中難免會有一些配件, 如:太陽眼鏡、圍巾、耳環等,或是外在環境因素,如:光線、角度等, 這些配件或是環境因素在人臉圖片中稱之為多重屬性。 本實驗室利用既有的 Local Discriminant Embedding (LDE) 演算法作為延伸,達到多重屬性分類的目的。
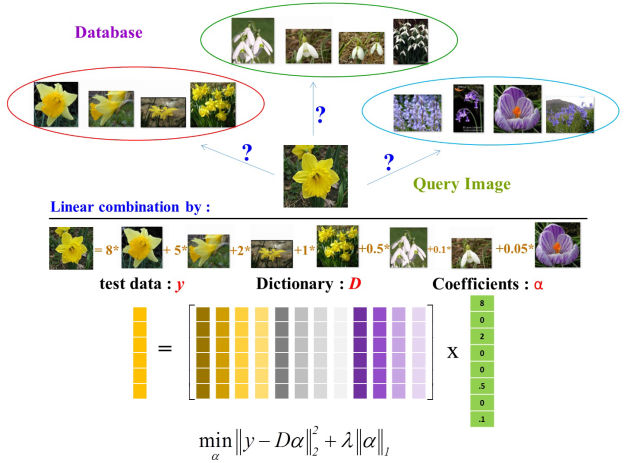
稀疏編碼 Sparse Coding
近年來 sparse coding 在電腦視覺以及影像處理的領域相當受到歡迎,sparse coding 由輸入資料、dictionary 以及輸入資料對應的線性組合組成。 sparse coding 可以用來影像除噪 (denoising)、影像復原 (restoration),以及影像分類 (classification) 等工作。 本實驗室基於稀疏編碼著重於二個研究方向:多重屬性影像分類以及巨量資料的稀疏編碼。